Should you be using semantic search?
With all the hype around semantic search you might be asking, should you be using it too? We'll walk through what semantic search is and how you can use it to augment your search.

I’ve been getting this question a lot recently. It’s a fair question especially as people have been using the same tools for search for a long time. I’ll walk you through some of the challenges with search as it currently exists. Then I’ll show why and how to use semantic search in OpenSearch. Finally, we will cover some of the potential challenges with using vector search. While it has quite a few upsides they come at a cost.
OpenSearch's default search
OpenSearch by default is a lexical document store. This means it takes keywords from a query and tries to find them in the documents from your index. It can enrich documents using different analyzers like the english language analyzer. This one does stemming, where it evaluates run and running to the same word as they have the same root.
As OpenSearch finds documents with words matching your query it begins to calculate a relevance score. The score is based on how many times the words appeared in any document and how many other documents contain that word. This helps to filter out common words like the or and which exist in many documents.
These techniques have been the foundation of the search industry for years now. They do poorly when we have words that may be semantically similar like sprint and run. We may know intuitively that these words are similar. Unless we create some fairly complicated synonym rules, documents with run won’t be returned if we have sprint in our query.
Even with synonym rules lexical search engines still struggle with context. Say we have a document with the phrase racecar driver and another with golf driver. If we search for supercar driver both of those documents will be returned because the term driver shows up in both.
With semantic search
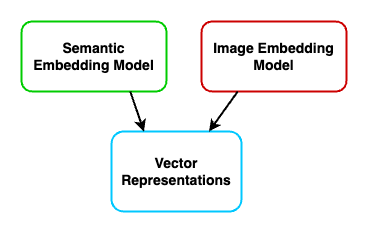
This is where semantic search comes into play. With machine learning (ML) models, we can create a representation of what a document means. The representation is encoded as a vector (an array of floating point numbers). Vectors are the way to represent and compare the outputs of these ML models. As shown above, many different types of models may output vectors that can be searched and compared to each other.
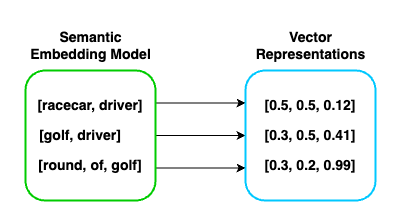
Using one of these semantic models we encode our documents as a vector. Above I have shown an example of what the output might look like. Even though each of the inputs are different lengths they are output to a consistent sized array of floating numbers between 0 and 1. Since there are 3 floating points per array you would say this is a 3 dimensional vector. When we run this we will use msmarco-distilbert which outputs vectors that have 768 dimensions.
Next, I'll plot these vectors so we can see what they might look like. OpenSearch uses some fancy linear algebra to compare vectors. This happens with functions like cosine similarity or dot product. I don't think there is any way to represent what's happening in a nice visual way so we will simplify it with the below plot.
![An x, y graph with three vectors plotted (points with arrows). [round, of, golf] plotted at 0.3, 0.2. Directly above it is [golf, driver] plotted at 0.3, 0.5. Finally to the right of that point at 0.5, 0.5 is [racecar, driver].](https://tippybits.com/content/images/2024/05/EmbeddingSpace-3.png)
I've also used the words next to the points to show the original documents these represent. As we can see words that are similar share dimensions. For example, it seems things related to golf share the 0.3 dimension on the X axis, whereas things related to driving are sharing a 0.5 dimension on the Y axis.
Now if we were to execute our search for supercar driver we would need to run the search phrase through our embedding model. This may look like [0.47, 0.5, 0.01]. This embedding will then be compared with the other vectors to find the ones that look most like it. Now we can see that our document racecar driver is very similar to supercar driver.
![The same graph as above however very close to [racecar, driver] on the left is [supercar, driver] plotted at .45, 0.5.](https://tippybits.com/content/images/2024/05/Vector-Search-Example.png)
So semantic search is used when your users might not know the exact words they need to use to find the documents they want. Question-answering systems will likely be the type of systems where adding semantic search will improve the quality of result matches. These are the types of systems where people are asking questions and may not use the exact words in the documents.
Creating a semantic search experience in OpenSearch
The best way to get started is to use the OpenSearch connectors. These will allow you to build an ingestion pipeline that will automatically create embeddings for data as it’s sent into your cluster. These examples should be run from the OpenSearch devtools.
First, we will set up the cluster to support ML workloads and allow access to connectors. Below are the settings that we need to enable to run models in OpenSearch.
PUT _cluster/settings
{
"persistent": {
"plugins": {
"ml_commons": {
"allow_registering_model_via_url": "true",
"only_run_on_ml_node": "false",
"model_access_control_enabled": "true",
"native_memory_threshold": "99"
}
}
}
}Next, we create a model group for access control. Save the Model ID for later
POST /_plugins/_ml/model_groups/_register
{
"name": "Model_Group",
"description": "Public ML Model Group",
"access_mode": "public"
}
# MODEL_GROUP_ID:
Here is a sample using msmarco-distilbert as a local embedding model. This is going to be one of the most straightforward ways for us to test this. In the below make sure to past the model group ID we saved above. Now we are going to register the model into our cluster. This downloads the model for use locally. Remember to save the task ID generated here for the next steps.
POST /_plugins/_ml/models/_register
{
"name": "huggingface/sentence-transformers/msmarco-distilbert-base-tas-b",
"version": "1.0.2",
"model_group_id": "EPBkeI8BFtCmbnffsBiF",
"model_format": "TORCH_SCRIPT"
}
# TASK_ID:
Now we need to wait for the model to be pulled down and deployed. To check the status we can call the following:
GET /_plugins/_ml/tasks/<TASK_ID>
# MODEL_ID:
When the state changes to completed then the operation is complete and we can grab the Model_ID and deploy it in our cluster.
POST /_plugins/_ml/models/<MODEL_ID>/_deploy
# TASK_ID
This will result in a new task ID that we will use to check if the model gets deployed. Once this task shows as complete then we will know the model is ready for use.
GET /_plugins/_ml/tasks/<TASK_ID>
We can test the model by trying to embed some text:
### Testing the Embedding Model
POST /_plugins/_ml/_predict/text_embedding/<MODEL_ID>
{
"text_docs": ["This should get embedded."],
"return_number": true,
"target_response": ["sentence_embedding"]
}If that returns a large array of floating point numbers we are in a good state! Now we can use the model in our ingestion and search pipeline. Below embedding-ingest-pipeline is just an arbitrary name for the pipeline. The important part is the field_map section. What happens in the ingestion pipeline is it will look for the key field, in this case content, and will send that to our ML model to get embedded. It will then store the result in the content_embedding field. The key field needs to match the name of the field you wish to embed in your source data but the value field there is arbitrary.
PUT _ingest/pipeline/embedding-ingest-pipeline
{
"description": "Neural Search Pipeline",
"processors" : [
{
"text_embedding": {
"model_id": "<MODEL_ID>",
"field_map": {
"content": "content_embedding"
}
}
}
]
}Now we create a hybrid search processor. This will allow us to do both traditional keyword search, alongside vector search and combine the result sets in the end. Here hybrid-search-pipeline is the name of our search pipeline. It can be whatever you would like so long as you use the same name when connecting it with your index.
## Put the search pipeline in place
PUT _search/pipeline/hybrid-search-pipeline
{
"phase_results_processors": [
{
"normalization-processor": {
"normalization": {
"technique": "min_max"
},
"combination": {
"technique": "arithmetic_mean",
"parameters": {
"weights": [
0.3,
0.7
]
}
}
}
}
]
}Now we can finally create an index mapping for our documents! I am saying index mapping as this simply specifies how certain fields should be mapped when being pushed into our OpenSearch index. Again documents is an arbitrary index name picked for this demo.
PUT /documents
{
"settings": {
"index.knn": true,
"default_pipeline": "embedding-ingest-pipeline",
"index.search.default_pipeline": "hybrid-search-pipeline"
},
"mappings": {
"properties": {
"content_embedding": {
"type": "knn_vector",
"dimension": 768,
"method": {
"name": "hnsw",
"space_type": "innerproduct",
"engine": "nmslib"
}
},
"content": {
"type": "text"
}
}
}
}
Finally, you should be able to insert documents into your index! I would recommend using the `_bulk` endpoint. It is the most straightforward way to send documents into an index in OpenSearch. Below is an example of what a bulk request looks like. The bulk endpoint expects newline delimited JSON. The first line is the action you wish to perform, and the second line is the document for that action to apply to.
POST /documents/_bulk
{ "index": {"_id": "1234" } }
{ "content": "There once was a racecar driver that was super fast"}
{ "index": {"_id": "1235" } }
{ "content": "The golf driver used by tiger woods is the TaylorMade Qi10 LS prototype"}
{ "index": {"_id": "1236" } }
{ "content": "Some may say that supercar drivers dont really mind risk"}Once your data is in we can finally pull it all together with a search.
GET /documents/_search
{
"_source": {
"exclude": [
"content_embedding"
]
},
"query": {
"hybrid": {
"queries": [
{
"match": {
"content": {
"query": "sports automobile"
}
}
},
{
"neural": {
"content_embedding": {
"query_text": "sports automobile",
"model_id": "<MODEL_ID>",
"k": 5
}
}
}
]
}
}
}
Finally, here are the results! None of the documents contained the word sports or automobile. Our search was able to determine that the first two documents were more related than the last one. In a production system, we would want to filter out results less than a certain threshold.
"hits": [
{
"_index": "documents",
"_id": "1234",
"_score": 0.7,
"_source": {
"content": "There once was a racecar driver that was super fast"
}
},
{
"_index": "documents",
"_id": "1236",
"_score": 0.17148913,
"_source": {
"content": "Some may say that supercar drivers dont really mind risk"
}
},
{
"_index": "documents",
"_id": "1235",
"_score": 0.00070000003,
"_source": {
"content": "The golf driver used by tiger woods is the TaylorMade Qi10 LS prototype"
}
}
]Challenges with semantic search
Even though in this example we were able to see a huge benefit from semantic search not every use case will see the same results. The first challenge is when your business uses different terms and language than was represented in the training data. For example, in the world of search relevance, there are acronyms like bm25, tf-idf, and ndcg@10. These are industry specific and many language models won't know how to embed them. This could result in random documents being returned. One strategy is using a semantic model that has been fine-tuned on your data.
Another challenge with semantic search is it is more resource-intensive than lexical search. For example, HNSW is very memory intensive as all the vectors are stored in memory (check this memory sizing documentation). Additionally, ingestion takes longer as documents need to be run through the embedding models. Even with all this, several people will see huge benefits from adding vector search to their stack.
If you'd like help evaluating semantic search I am here to help! Check out my services page and schedule some time with me. I'd love to talk about what you are building and if vector search is a good fit for you!