What no one told you about vector search
As your adopting vector search missing these few things could make or break your experience. These are the things I've found nearly everyone misses when they are rolling out vector search.

My background was never search or relevance engineering. For the ~7 years before I started working with OpenSearch I had been doing DevOps, data engineering, and software engineering. That's why I had such a hard time when vector search started to become so popular. It felt like every time I felt I knew what was happening my understanding was shaken up. Turns out it's not just me. I've talked with countless engineers recently who have hit some of the same roadblocks that I'll be mentioning.
While I can't share everything I've learned in just one blog here let's go through some of the top issues I've seen over and over. These are the ones that would typically stop a company from ever adopting vectors into their search workflow.
Machine learning models have a limited input
I was just talking to a company a few weeks back about their search use case. When I asked them if they had tried semantic search they said they had and the results were tragic. Shocked to hear this I asked why they thought it didn't work. From my perspective, I felt their use case was a perfect fit for vector search.
After digging in, I found that they were embedding documents that were tens of thousands of words long. This may seem reasonable until we start to look at how vector embeddings work in general and then specifically in OpenSearch.
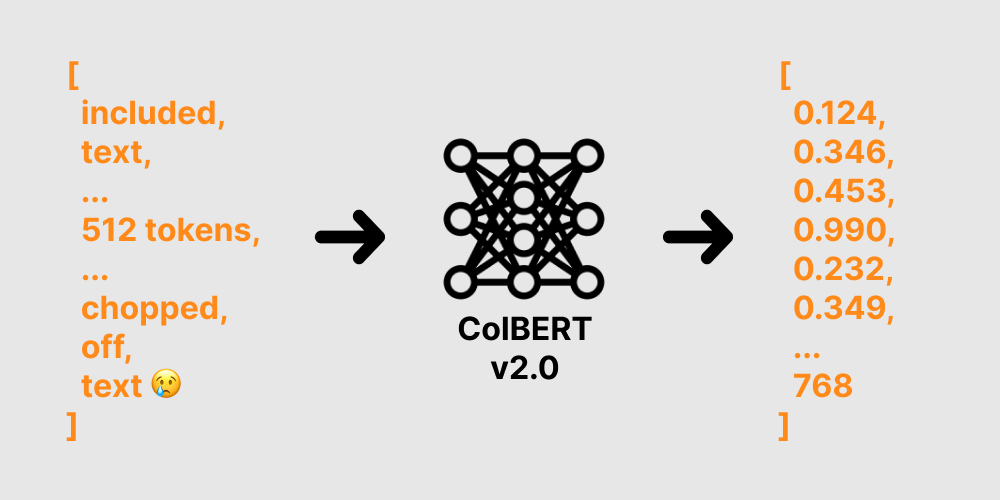
When we embed documents we send them through a machine learning (ML) model. These models take in a fixed number of tokens and will output a representation as a vector of a fixed size. Tokens in most cases are just words separated by spaces. ColBERTv2.0 for example takes in 512 tokens by default and outputs a vector with 768 floating-point numbers.

So how does OpenSearch handle text longer than the input maximum for a model? It truncates it. By this, I mean if you ingest a 1000-word document and the model only supports 512 tokens OpenSearch will simply cut your document down to 512 tokens and discard the rest. This is why the above company had bad relevance when they were embedding their hyper-long documents. Their documents were being cut down to the first 512 tokens and the remaining was discarded.
The right way to handle documents with longer inputs depends on how you plan to query them. No matter what you do though I feel like cutting documents without alerting the user is bad UX. This is why I've laid out the following proposal to change this pattern in OpenSearch. Check it out and please comment your thoughts!
 opensearch-project
opensearch-projectHandling longer documents
So with a fixed number of input tokens, how can these models embed longer documents? There are a few strategies we will explore here. Which you end up choosing depends on how you plan to access the documents. I think this will make a bit more sense as we start working through each of the scenarios.
You need chunks! Chunking is when we cut our documents into pieces. While this may seem like a simple task there are quite parameters to tune here. How big are our our chunks? Do they overlap? By how much? How do we represent these in OpenSearch?
Let's start with your goals for these documents. What do you plan on doing with them? For example, the company we mentioned above helped their users find books matching their search. Others may be looking to return just the most relevant chunk of a document for use in a retrieval augmented generation (RAG) pipeline.
Strategies for vector ingestion
When your goal is to retrieve a whole document I'd recommend using OpenSearch's ingestion pipeline for chunking documents. This method will chunk the target field from the document into multiple vector embeddings. These will be stored in a nested field. This method comes with a few distinct advantages. With the score mode as "max" we can find the document that has the highest matching passage. We can also use "avg" to see which document has the most relevant chunks related to the query.
GET index_name/_search
{
"query": {
"nested": {
"score_mode": "avg",
"path": "passage_chunk_embedding",
"query": {
"neural": {
"passage_chunk_embedding.knn": {
"query_text": "document",
"model_id": "-tHZeI4BdQKclr136Wl7"
}
}
}
}
}
}
Again this is the strategy I would recommend for companies who's goal is to return the whole document. It's going to dramatically simplify your ingestion setup and your relevancy scoring. For people interested in returning the individual parts of a document for a RAG type use-case I am going to recommend using an external chunker such as Haystack's document splitter or LangChain's text splitter. These will allow you to split the documents into individual chunks and store them as separate documents. This is because the goal of RAG is to find the most relevant chunk to provide context for LLM generation.
The final boss - capacity planning
Once you have your strategy for ingesting vectors planned you need to start capacity planning. Vectors operate a bit differently in OpenSearch than typical documents. First off, embedding and ingesting embeddings takes significantly longer than ingesting text. It's important test and see how long this process takes for your documents.
Your nodes also need to be right-sized for vector search. Assuming you are using HNSW, which I feel most people will be, all of the vectors are going to be stored in memory. Below is the rough calculation for memory use with HNSW. This is with the out-of-the-box configuration.
1.1 * (2 * <dimensions> + 128) * <num_vectors> ~= Bytes
# So for a 512 dimension vectors with 1,000,000 vectors:
1.1 * (2 * 512 + 128) * 1,000,000 ~= 1267200000 Bytes or 1.26GBI'd recommend using memory-optimized instances for vector search. In AWS these are the "R" instances. One of the interesting things about vectors in OpenSearch is they are loaded in memory space outside of the JVM. So if 50% of your memory is dedicated to the JVM as typically recommended then you will have the remaining 50% for the OS and vector storage.
Is that it?
Not even close! There is so much to know when it comes to vector search. The things I've covered here are just enough to help you get a solid start. There is still model fine-tuning, relevance engineering, hybrid search, and the list goes on. For a deeper dive on vectors in OpenSearch check out this fantastic blog from AWS.
If your company would like to evaluate vector search I am here to help! I've worked with dozens of customers while working at AWS, get started with vector search and I'd love to help you too! Schedule some time with me for your free consultation!