How Search Engines Find Cat Videos
The how and why behind how search engines work to find us the content we want in under a second.
The how and why behind the workings of search engines
Search engines somehow scour millions of pages on the internet in under a second, finding us the cat videos we wanted. They do this with some serious technology and an amazing process.
Discovering Content
The first job of a search engine begins well before you ever open your browser. Search engines have to start by scouring the web for all sorts of content. Web crawlers visit one site after the next to collect the information on pages.
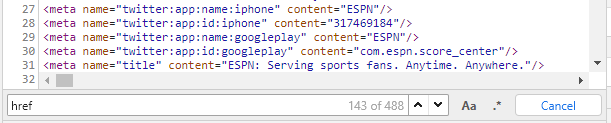
Web crawlers work by visiting a website and scanning it to find all of the links on a page. For each link, it finds it will add those to a list of links it needs to visit. From each of those links, it will visit the web page and find more links. This method is really effective it turns out. Below is a snippet from ESPN’s website which has 488 links on their web page. Some of these are internal links and others link to scripts but you can see that pages tend to be heavy in links.
Indexing Pages
While the web crawler is moving along visiting pages it is collecting information off each page and adding it to an index. An index is an organized list of data used for searching. There are a lot of different formats this information can take.
Metadata is one of the primary attributes collected from each webpage. To put it simply metadata is information about the page. It provides a view into what type of content is on the page along with, information that the page features. Here is a small example of what metadata looks like using the metadata on one of my other articles “What You Didn’t Know Google Knows”.
Here we can see a lot of information about what you can find in that article. For example, you can see the description, title, and which publication features the article. Search engines collect this and add it to their index so they can better determine what is on the page.

In their index, they will also store the rank of a page. Search engines rank content based on how well written they are and how readable a page is. Arguably one of the biggest factors for rank is how many places link to that content as that can establish its popularity and relevance.
Categorizing Content
After scraping the page a Natural Language Understanding engine processes the information. One great example of this is IBM’s Watson which we will use to process an article “Installing Kubernetes for Ubuntu in Virtual Box”.
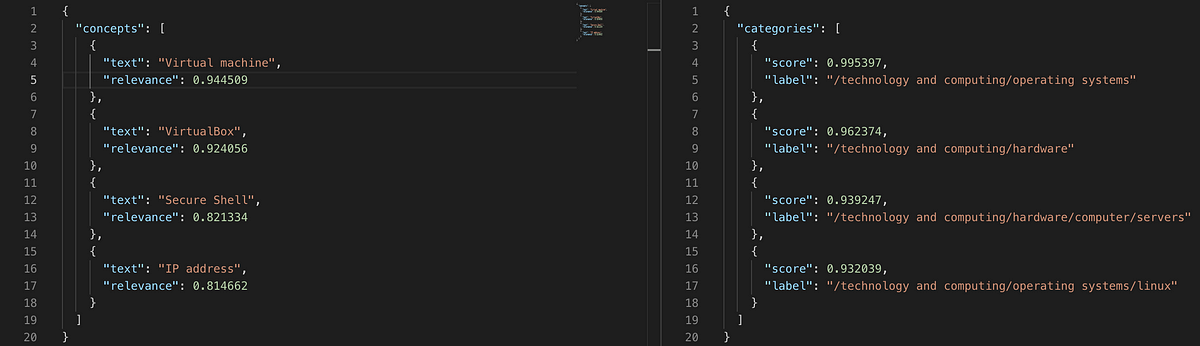
As seen below Watsons Natural Language Understanding extracted the concepts and categories from that article. On the left, we can see concepts it was able to pull out in the text field and how relevant Watson thought they were. On the right, we can see the categories it thought this article fell in. These might be used to recommend articles to people who are interested in certain content.
Searching!
Finally, you are ready to put your search into the Search Engine! But, wait! There is one last bit of magic that exists in between you and your results. That last leg is the query engine. The query engine will look over what you have typed in and check for the following things:
- Pre-query recommendation: Search engines receive a notification every time you enter a letter into the browser box. When they receive it they do a pre-check to see if they can suggest any content to you.
- Spell check: If not it will typically correct and then prompt you asking if their correction was appropriate.
- Direct quote analysis: Here the search engine will use some logic to determine if what you typed in was a quote. If it was then it will only look for exact matches.
- Synonym analysis: Here the search engine will see if what you typed in has any other synonyms that can be used and will search for those as well.
After all the magic in the world happens here you can finally 1,620,000 million results for the query, “cats scared by cucumbers” in .74 seconds. This is a massive oversimplification of how search engines work but the gist of it.
If you want to see more articles like this explaining technologies leave a clap or a recommendation in responses below.