Easier Web-Scraping in Python
Targeting just the data you want

Every day, I see guides about how to scrape the web scrolling across my feed.
All are using some combination of beautiful soup and puppeteer or selenium. But when you’re just looking to scrape some simple data, it may be easier to reverse engineer the website you are scraping.
Reverse Engineering Isn’t Scary
When I say reverse engineering, I simply mean look at how the information gets there, and see if there is a way to get just the data you are looking for.
For this example, we will be looking at Smedian.com because I wanted a large list of Medium articles for another scraping project I am working on.
1. Research the Webpage
Before getting too far into researching, check if there is a robots.txt or Terms and Conditions. Those will specify if it’s safe to scrape their website. It’s not worth getting into trouble with Johnny Law over a little data.
For robots.txt, you would check at the base URL like so: https://smedian.com/robots.txt. If you visit that link, you’ll be welcomed with a 404 — which means it is safe to scrape.
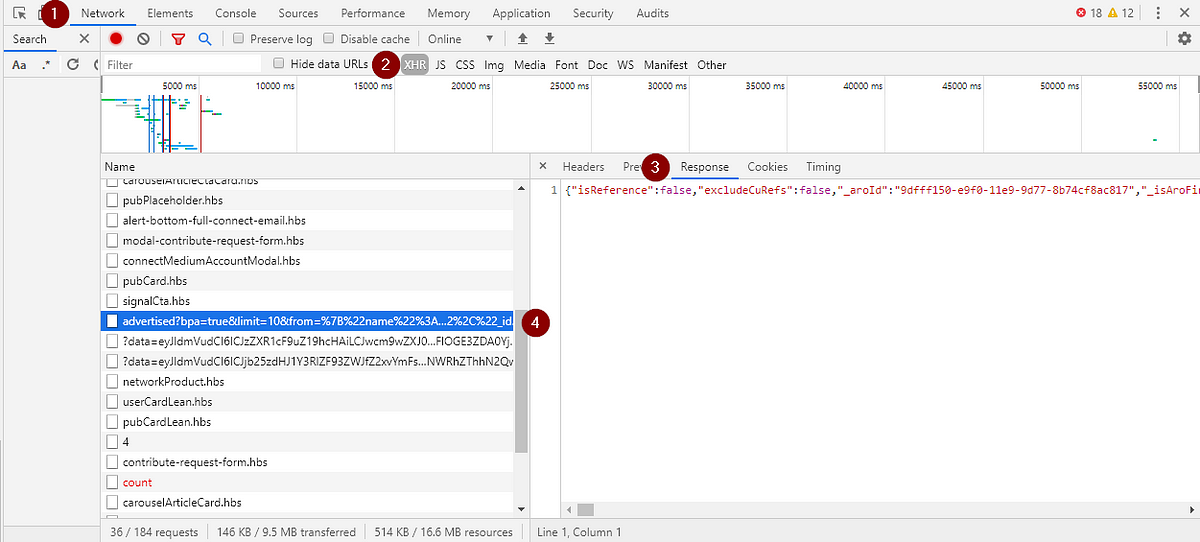
When I am scraping, I look through the network logs, filtering down to XMLHttpRequest (XHR), which are typically data requests. I am typically looking for what looks like a query and JSON response.
After finding what looks like an endpoint shown below, I will copy the body of the JSON and see if keywords I want from the page are in the JSON. If they are, then I will start working off the webpage.
2. Analyzing the Request URL
Here, I will recommend you be as lazy as you can.
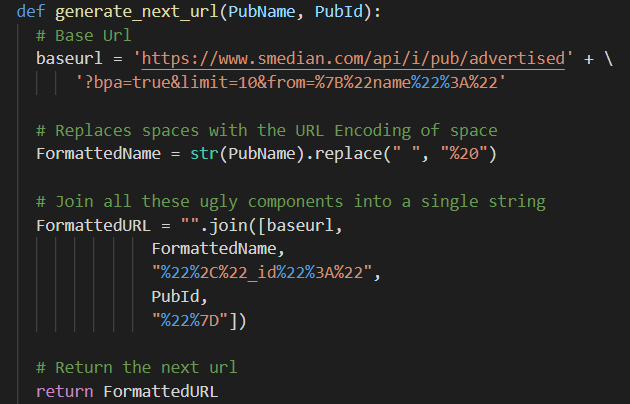
When I identified the URL I wanted to use (shown below), the first thing I saw was the limit parameter. I plugged in a large limit to see if I even needed to scrape the article. Or, at least, I thought I did. More on that later. After seeing this didn't work, I began to deconstruct the URL.https://www.smedian.com/api/i/pub/
advertised?
bpa=true&
limit=700&
from=%7B
"name"%3A"<%20BE%20OUTSTANDING%20%2F>"%2C
"_id"%3A"5927167d5fbc457423b176fc"%7D
From the URL, I found that it worked by looking at the name and ID of the last article in its list to request the following article. Thankfully, they put the parameters needed to request the next set of records in a little data structure at the beginning of the JSON:"paging": {
"limit": 10,
"canLoadMore": true,
"total": null,
"from": {
"name": "Waves Token Movement",
"_id": "5cef369a32628075008a0bf9"
},
"sortOrder": 1
}
With this at hand, I began working on a janky function to generate the URL for the next set of data in the sequence.
It combined the base URL, formatted name, ID tag, and publication ID together into one URL.
You’ll note as well that I’m casting the publication name to string, as one of them was just a number. Python tried interpreting it as such.
3. String It All Together
I use the following three functions to string it together.
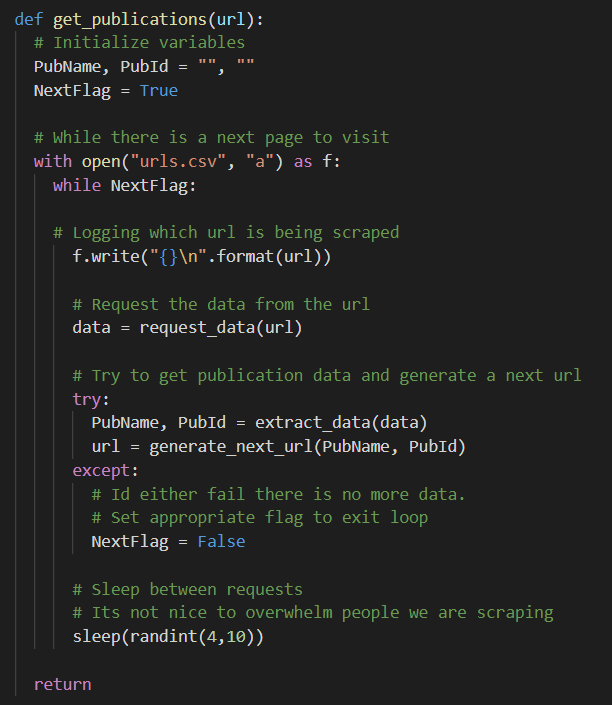
Get_Publications uses a seed input URL to start the process. Next, it will open a CSV for logging the request URL it’s working with. Then it loops, getting the data with request_data(URL), parsing it with extract_data(data), and then generating the next URL to process.
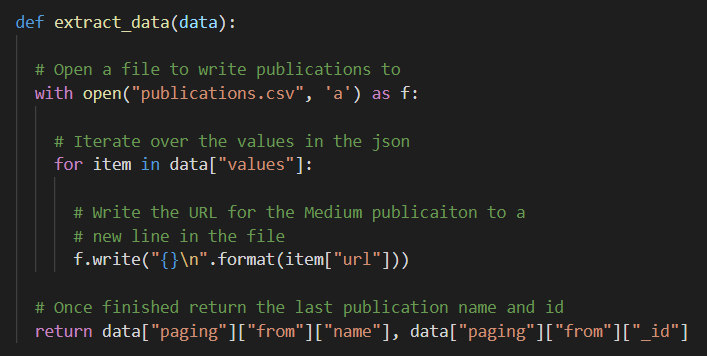
Extract_data logs the publication URL to a specific file and returns the name and ID of the last article to generate the next query string.
Also, request_data uses the requests module to get the data and return the JSON body.

Conclusion
And that is it. Thirty minutes of hacking away at it, and I have generated some really ugly code that saves me some time manually copying and pasting all the data.
It may seem strange to post such ugly code and publish it on Better Programming, but the point here is sometimes the value of writing beautiful code is just not there. I wrote this code to use one time to extract some data. If I needed to support it for longer, I would take some time to do proper error handling and type checking. But it works, and it saved me time overall — which is all I’m concerned with here.
Also, I’ll point out if I had paid better attention to what I was doing earlier, I would have saved 20 minutes writing code to request and generate URLs. I had tried changing the limit on another endpoint while I was researching, and that didn't work. This endpoint, however, is not limited, so I could have simply requested all the JSON upfront and focused on parsing it.
Another side note is to take everything on the internet with a grain of salt. Smedian advertises 797 publications; however, there were only 721 in my count with two duplicates. Not sure why, but they haven’t responded to my tweet.