Simple Architecture for Creating a Scaleable Search Engine
The easy way to build a search engine How to create a simple search engine using, Kafka, Kubernetes, Python, MongoDB, and Elastic search.

The easy way to build a search engine
This article has been sitting in my to-do queue for way too long. The more I research, the deeper it seems to go. Through my research, I believe I have actually found an easy way to architect a search engine. It will be lacking many of the features others have, such as synonym substitution or image classification. BUT, it will be a search engine and it will scale.
Search Engine Core Services
A little background here is necessary. Search engines have 3 primary services that keep them going.
Crawlers are the first service. This is a program that will visit a web page, grab all the links off that webpage, and then visit them. This is how search engines are constantly finding new content and staying up to date. These often have to use rotating proxies to ensure that a website does not block them from making too many requests. The proxy provider we will use is infactica.io.
Another important note about crawlers is we must respect the robots.txt. Not every site will have one but for the ones that do, we must be respectful and only scrape according to the site's guidelines.

You may notice here that above I am not actually pulling the URLs out in this service. The reason is each service should have one defined job and execute only that job. Below is the service to pull URLs out of the page and store them.

This service shares roles with the webpage processors as it is reading the page. It just so happens to have some overlap with the crawling service as well as feeds the topics.
Webpage processors read over the content on a page and break it down into simpler forms. These forms could be grouping them by topic, keywords, or even sentiment (the emotion they convey). They also will extract the metadata from the page, which often contains keywords as well as a description.

Above is only the metadata processing service. This will be separate from the Natural Language Processing (NLP) service to add relevant information about the webpage.

Indexing is the process of organizing the information that is found in a way that can be easily searched. Typically indexes use the keywords and page rank in order to return the most relevant information. Indexing requires much in the way of research and development. Finding the most relevant search results depends on what you are searching for.
The service below doesn't care about the data it is given but pushes it into the search index.

The Architecture

Building a scalable architecture means we need to limit dependencies and enable processes to scale linearly. To do that we need to break each component out into one or more independent services. The other bit that needs to scale is the method of communication. Each service should not have to know where its data is ending up. The services should process data when prompted.
Three core technologies will enable us to meet the above requirements.
Kubernetes is a scalable Docker container platform. It allows you to set up servers without needing to know what containers will eventually run on them. This is a great way to ensure the software doesn’t care what hardware it runs on. In the same regard, the hardware should not care what software runs on it.
This is the container for all our services that were mentioned in the last section. It will allow us to scale each of the services to meet the demand.
Kafka will control all the data flow for the services. Here, containers will listen to and write to topics. Kafka’s topics are capable of having multiple of the same type of container process data on a topic without duplicating data. This way, all the services do not come crashing down if one service stops functioning.
In the previous section as well you may have noticed how each service had a similar format. They are all either consumers, producers, or consumers and producers of Kafka topics.
Elastic Search allows you to create a search index. Elastic search is a text-based search application. It allows you to use several different fields for searching. This way you can prioritize which values are the best indicator that a record matches a search.
Pulling It All Together
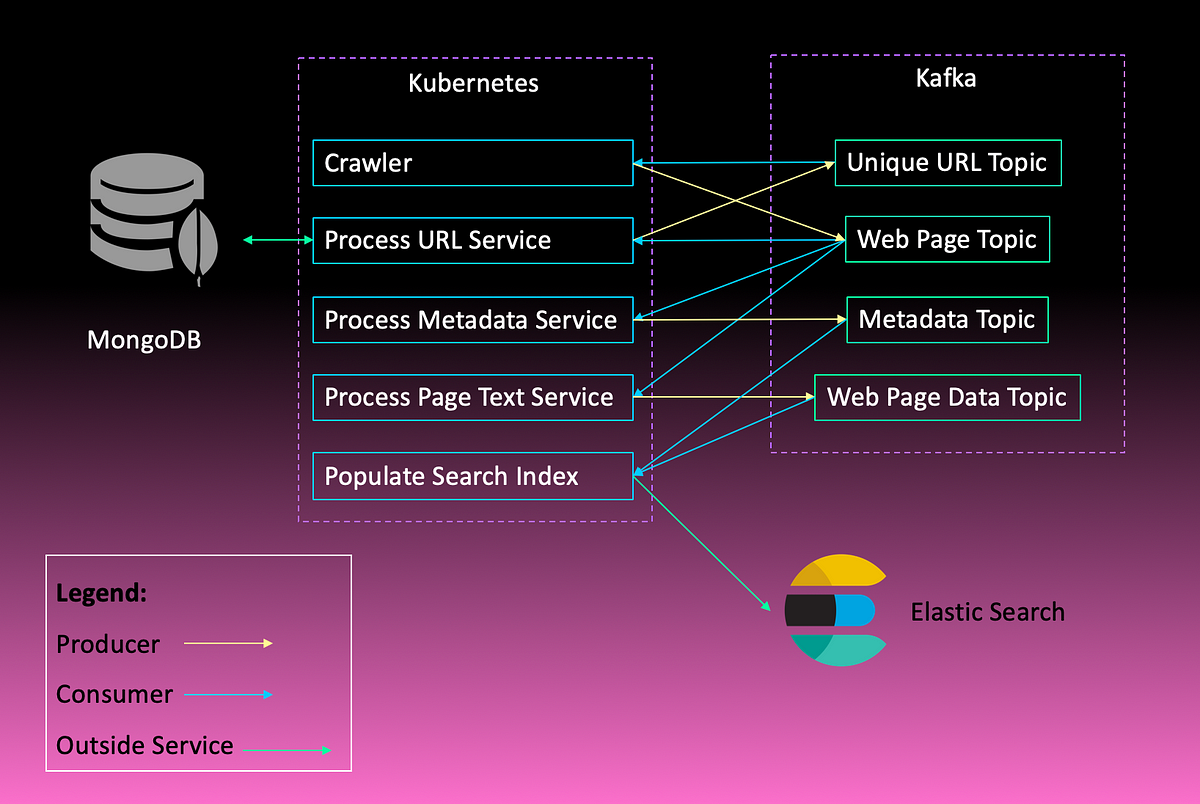
Wow… Well seems even a simple search engine isn’t all that simple after all. Above I have attempted to diagram the flow of data mentioned. We can have multiple subscribers to one topic which allows us to scale horizontally. You can see this by looking at the consumers of the web page topic. None of those services are dependant on the output from the others so they can all run side by side.
We created the plan for a search engine that is fairly modular, scalable, and robust. Having each service separated allows one or more processes to fail without taking the whole system down. Work may get backed up but that is the beauty of this system. You could simply scale the consuming services to catch up.
Follow along as I set out to create the services and search engine that I have described in this article.